
Introduction
YOLOv8 Architecture is the latest iteration of the You Only Look Once (YOLO) family of object detection models, known for their speed and accuracy. Developed by the Ultralytics team, YOLOv8 builds upon the success of its predecessors while introducing several key innovations that push the boundaries of real-time object detection.
Object detection involves identifying and locating objects of interest within an image or video. Traditional methods often relied on sliding window approaches, which were computationally expensive and slow. YOLO revolutionized the field by treating object detection as a single regression problem.
Instead of sliding windows, YOLO predicts bounding boxes and class probabilities for objects directly from the input image in a single forward pass, making it significantly faster.
YOLOv8 Architecture: Just Overview
The YOLOv8 architecture can be broadly divided into three main components:
- Backbone: This is the convolutional neural network (CNN) responsible for extracting features from the input image. YOLOv8 uses a custom CSPDarknet53 backbone, which employs cross-stage partial connections to improve information flow between layers and boost accuracy.
- Neck: The neck, also known as the feature extractor, merges feature maps from different stages of the backbone to capture information at various scales. YOLOv8 Architecture utilizes a novel C2f module instead of the traditional Feature Pyramid Network (FPN). This module combines high-level semantic features with low-level spatial information, leading to improved detection accuracy, especially for small objects.
- Head: The head is responsible for making predictions. YOLOv8 employs multiple detection modules that predict bounding boxes, objectness scores, and class probabilities for each grid cell in the feature map. These predictions are then aggregated to obtain the final detections.
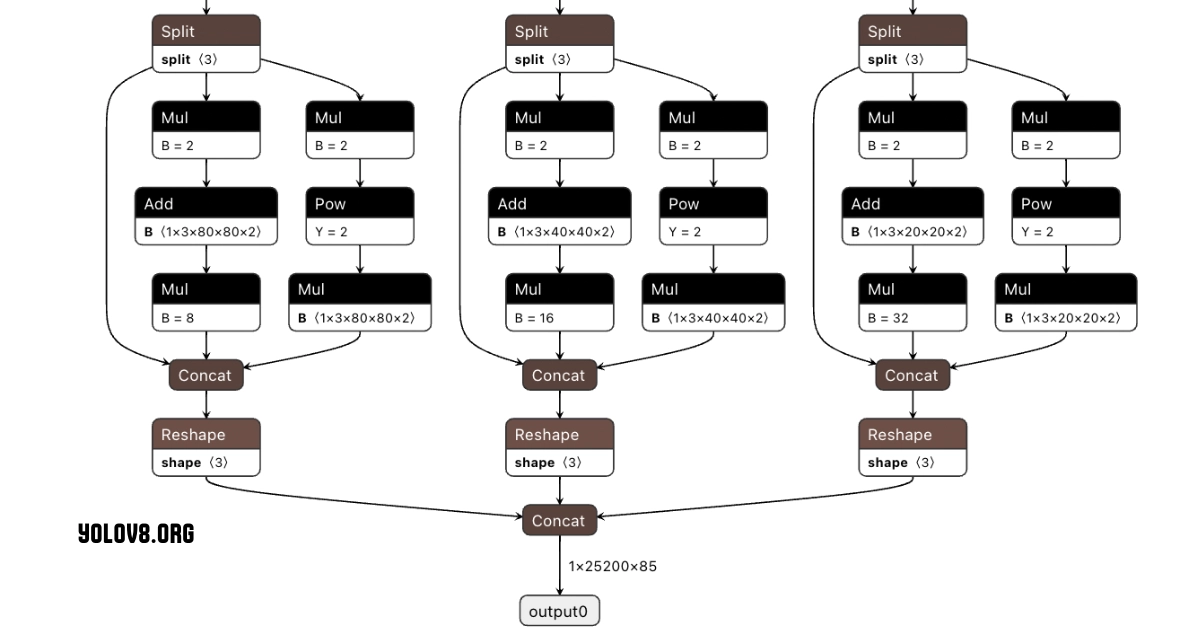
YOLOv8 vs YOLOv7: Key Differences and Improvements
YOLOv8 introduces several architectural and functional enhancements over its predecessor, YOLOv7. One of the most notable shifts is its move toward an anchor-free detection system, which simplifies training and inference. YOLOv8 also boasts faster training speeds, reduced memory usage, and improved precision-recall tradeoffs due to its updated backbone.
Another major upgrade is the built-in support for Ultralytics’ training tools and Python API, making it easier to implement, evaluate, and deploy. YOLOv8 also supports export to ONNX, CoreML, and TensorRT with fewer compatibility issues compared to YOLOv7. These changes reflect an emphasis on scalability and cross-platform flexibility.
Key Innovations in YOLOv8
Several key innovations contribute to YYOLOv8 Architecture’s impressive performance:
- Spatial Attention: YOLOv8 incorporates a spatial attention mechanism that focuses on relevant parts of the image, leading to more precise object localization.
- Feature Fusion: The C2f module effectively combines high-level semantic features with low-level spatial information, improving detection accuracy for small objects.
- Bottlenecks and SPPF: Bottlenecks in the CSPDarknet53 backbone reduce computational complexity while maintaining accuracy. Additionally, the Spatial Pyramid Pooling Fast (SPPF) layer captures features at multiple scales, further enhancing detection performance.
Data Augmentation and Mixed Precision Training:YOLOv8 Architecture leverages various data augmentation techniques to improve generalizability and reduce overfitting. Mixed precision training further enhances training speed and efficiency.
Benefits of YOLOv8
YOLOv8 offers several advantages over its predecessors and other object detection models:
- High Accuracy: YOLOv8 achieves state-of-the-art accuracy on various object detection benchmarks.
- Real-time Speed: The model boasts impressive inference speeds, making it suitable for real-time applications such as autonomous vehicles and robotics.
- Efficiency: YOLOv8 is lightweight and requires fewer computational resources than other models, making it ideal for deployment on edge devices.
- Open-source and Community-driven: YOLOv8 is open-source and backed by a vibrant community, fostering continuous development and improvement YOLOv8 Architecture.
Applications of YOLOv8
The versatility of YOLOv8 makes it suitable for a wide range of applications, including YOLOv8 Architecture:
- Autonomous vehicles: Object detection is crucial for self-driving cars to navigate safely and avoid obstacles.
- Security and surveillance: YOLOv8 can be used in security systems for anomaly detection, intrusion detection, and object tracking.
- Retail and manufacturing: The model can be employed for product identification, inventory management, and quality control in retail and manufacturing environments.
- Robotics: YOLOv8 empowers robots to perceive their surroundings YOLOv8 documentation and interact with objects intelligently.
- Medical imaging: The model can assist in medical diagnosis by automatically identifying objects in medical images, such as tumors or abnormalities.
YOLOv8 represents a significant leap forward in object detection technology. Its combination of high accuracy, real-time speed, and efficiency makes it a compelling choice for various applications across diverse industries.
As research and development continue, we can expect YOLOv8 to evolve further and push the boundaries of object detection even further.
YOLOv8 Integration with Ultralytics API
Ultralytics has streamlined the integration of YOLOv8 models into Python-based pipelines through its powerful API. This means you can now train, validate, and deploy object detection models using just a few lines of Python code.
Whether you’re performing real-time inference on video streams or batch-processing images, the Ultralytics API allows you to load pre-trained models, fine-tune parameters, and even visualize outputs using built-in utilities. This easy-to-use interface has made YOLOv8 an attractive choice for rapid development in computer vision projects.
Understanding YOLOv8 Anchor-Free Design
A key innovation in YOLOv8 is its anchor-free detection mechanism, which removes the need for predefined anchor boxes. Traditional YOLO models relied on these anchor boxes to predict object locations, often requiring careful tuning and prior knowledge of object sizes.
By adopting an anchor-free approach, YOLOv8 simplifies the learning process and improves performance on varied object scales and aspect ratios. This design also contributes to reduced model complexity and better generalization, particularly when training on datasets with unusual or irregular object shapes.
YOLOv8 Architecture: A Deep Dive into its Cutting-Edge Design
Object detection is a fundamental task in computer vision, with applications ranging from autonomous vehicles to surveillance systems. You Only Look Once (YOLO) has been at the forefront of object detection algorithms, and the latest iteration, YOLOv8, represents a significant leap in terms of accuracy and efficiency.
Now, we’ll take a deep dive into the YOLOv8 architecture, exploring its key components and innovations.
1: Introduction to YOLOv8
YOLOv8, short for You Only Look Once version 8, is an object detection algorithm designed to detect and classify objects in images with remarkable speed and accuracy.
It builds upon the success of its predecessors, addressing their limitations and incorporating advanced techniques to enhance performance.
2: YOLOv8 Architecture Overview
- Backbone Network
The backbone network is the foundation of YOLOv8 and is responsible for feature extraction from the input image. YOLOv8 employs CSPDarknet53, a variant of Darknet, as its backbone.
The CSPDarknet53 architecture introduces a novel Cross-Stage Partial (CSP) connection, enhancing the information flow between different stages of the network and improving gradient flow during training.
- Neck and Head Structures
YOLOv8 introduces a Path Aggregation Network (PANet) as the neck structure. PANet facilitates information flow across different spatial resolutions, enabling the model to capture multi-scale features effectively.
The head structure consists of multiple detection heads, each responsible for predicting bounding boxes, class probabilities, and objectness scores at different scales.
- Detection Head
The real innovation is in the detection head of YOLOv8. It utilizes a modified version of the YOLO head, incorporating dynamic anchor assignment and a novel IoU (Intersection over Union) loss function.
These improvements contribute to more accurate bounding box predictions and better handling of overlapping objects.
3: Training Strategy
YOLOv8 adopts a comprehensive training strategy to optimize its performance. One notable feature is the use of multiple training resolutions, allowing the model to learn from images at different scales YOLOv8 Architecture.
Additionally, the model utilizes a mosaic data augmentation technique, combining multiple images into a single training input. This approach enhances the model’s ability to generalize to diverse scenarios and improves its robustness.
4: Model Variants
YOLOv8 comes in different variants tailored for specific use cases. YOLOv8-C, YOLOv8-D, and YOLOv8-E represent different model sizes, with YOLOv8-D being the default configuration.
Users can choose a model variant based on the trade-off between accuracy and computational efficiency that suits their application requirements.
5: Performance Metrics
YOLOv8 has demonstrated state-of-the-art performance on popular benchmark datasets, such as COCO and VOC.
Its accuracy, combined with real-time processing capabilities, makes it a compelling choice for various applications, including object detection in videos, robotics, and more.
6: Open Source and Community Support
One of the strengths of YOLOv8 is its open-source nature. The codebase is available on GitHub, allowing researchers and developers to access, modify, and contribute to the algorithm’s evolution. The vibrant community surrounding YOLOv8 ensures ongoing improvements, bug fixes, and the incorporation of cutting-edge research YOLOv8 Architecture.
How to Fine-Tune YOLOv8 on Custom Datasets
Training YOLOv8 on your own dataset is straightforward, thanks to its simplified YAML-based configuration and dataset structure. You’ll start by organizing your dataset into train, val, and optionally test directories, with corresponding label files in YOLO format.
Next, update the dataset YAML file to reflect the correct class names and file paths. Using the command-line interface or Ultralytics Python API, you can launch training with options for batch size, epochs, image size, and optimizer settings. YOLOv8 supports augmentation strategies like mosaic and mixup to enhance generalization during training.
YOLOv8 Deployment on Edge Devices (NVIDIA Jetson, Raspberry Pi)
Deploying YOLOv8 on edge devices like NVIDIA Jetson or Raspberry Pi allows you to bring AI to environments with low latency requirements and limited internet access. The model’s lightweight architecture and efficient processing make it ideal for these constrained platforms.
To deploy on Jetson, you can export the model to TensorRT using ONNX as an intermediary. Raspberry Pi deployments typically involve using the PyTorch model with OpenCV or integrating with Coral accelerators. Either way, you get powerful object detection capabilities at the edge with minimal hardware overhead.
Real-World Use Cases of YOLOv8 in Industry
YOLOv8 is already making an impact across industries—from retail analytics and warehouse automation to medical imaging and traffic surveillance. In retail, it helps monitor shelf stock and track foot traffic. In logistics, it’s used to detect damaged parcels and optimize loading workflows.
Healthcare providers have begun using YOLOv8 to detect anomalies in radiology images. In smart cities, traffic authorities deploy it for real-time vehicle and pedestrian tracking, enhancing safety and optimizing flow. These case studies showcase the model’s versatility and efficiency in real-world scenarios.
Conclusion
YOLOv8 stands as a testament to the continuous evolution of object detection algorithms. Its innovative architecture, training strategy, and performance metrics position it as a leading solution for real-time object detection tasks.
As the field of computer vision advances, YOLOv8 serves as a benchmark for future developments, pushing the boundaries of what is achievable in object detection.
Whether deployed in autonomous vehicles, surveillance systems, or other applications, YOLOv8’s versatility and accuracy make it a powerful tool in the computer vision landscape.
FAQS (Frequently Asked Questions)
Q#1: What are the key changes in YOLOv8’s architecture compared to previous versions?
YOLOv8 boasts several architectural updates targeted at boosting both accuracy and speed. These include YOLOv8 Architecture:
- Stem tweak: Reducing the first convolutional kernel size from 6×6 to 3×3 for efficient image abstraction.
- Backbone bottleneck tweak: Upscaling the first convolutional kernel in the bottleneck area from 1×1 to 3×3 for better feature extraction.
- Backbone building block swap: Replacing the C3 block from YOLOv5 with a new, more efficient design.
- Anchor-free head: Implementing a novel anchor-free head for object detection, eliminating the need for predefined anchor boxes.
- New loss function: Utilizing a modified loss function focusing on both bounding box location and classification confidence.
Q#2: How does YOLOv8 balance accuracy and speed?
YOLOv8 strikes a strong balance between these two crucial aspects. Its architectural improvements and anchor-free head contribute to higher accuracy compared to earlier versions, while the optimized stem and backbone tweaks facilitate faster inference speed YOLOv8 Architecture.
Additionally, YOLOv8 offers a range of pre-trained models with varying accuracy-speed trade-offs, allowing users to choose the best fit for their specific needs.
Q#3: Is YOLOv8 suitable for real-time object detection applications?
Absolutely! YOLOv8’s emphasis on speed makes it ideal for real-time scenarios. Depending on the chosen model size and hardware platform,
YOLOv8 can achieve impressive inference speeds ranging from tens to hundreds of frames per second, perfectly suited for applications like autonomous vehicles, robotics, and video surveillance.
Q#4: How does YOLOv8 compare to other state-of-the-art object detection models?
YOLOv8 holds its own against contemporary models in terms of both accuracy and speed. Benchmarking results show it achieving competitive mAP (mean average precision) scores while maintaining real-time inference capabilities. Its user-friendly API and extensive documentation further increase its appeal for various applications YOLOv8 Architecture.
Latest Post
- How To Get A Free Domain And Hosting For Lifetime?
- Interpreting YOLOv8 Metrics: A Practitioner’s Guide to mAP, IoU, and Confusion Analysis
- Which algorithm does YOLOv8 use?
- How Many Classes Are in YOLOv8?
- What is the real world application of YOLOv8?
Per chi desidera informarsi in modo chiaro e dettagliato sul mondo dei casinò online, Napolipizzeria rappresenta un punto di riferimento utile per comprendere le principali caratteristiche dei casinò non AAMS con deposito minimo di 10 euro. Questo tipo di piattaforme sta attirando sempre più attenzione grazie alla possibilità di iniziare a giocare con un investimento ridotto.
Negli ultimi anni, il settore del gioco online ha subito una profonda trasformazione. Sempre più utenti cercano soluzioni flessibili che consentano di testare un casinò senza impegnare somme elevate fin dall’inizio. Il deposito minimo di 10 euro risponde perfettamente a questa esigenza, offrendo un accesso graduale e controllato all’esperienza di gioco.
Questa modalità è particolarmente apprezzata dai nuovi giocatori, che spesso preferiscono un approccio prudente. Iniziare con una cifra contenuta permette di valutare la piattaforma, esplorare l’interfaccia, testare i giochi disponibili e verificare la qualità del supporto clienti prima di investire importi più consistenti.
Un aspetto fondamentale da considerare nella scelta di un casinò non AAMS è la sicurezza. Le piattaforme affidabili adottano tecnologie avanzate per la protezione dei dati personali e finanziari degli utenti. La crittografia delle informazioni, l’utilizzo di sistemi di pagamento riconosciuti e la trasparenza delle condizioni contrattuali sono elementi essenziali per garantire un ambiente di gioco sicuro.
Oltre alla sicurezza tecnica, è importante valutare anche l’affidabilità dei giochi offerti. I casinò più seri utilizzano software certificati che assicurano risultati casuali e imparziali. Questo garantisce che ogni partita si svolga in modo equo, aumentando la fiducia degli utenti nella piattaforma scelta.
Dal punto di vista dell’offerta, i casinò non AAMS con deposito minimo di 10 euro propongono solitamente una vasta gamma di giochi. Le slot online occupano un ruolo centrale, grazie alla loro varietà e alle funzionalità innovative. Grafica moderna, bonus integrati e meccaniche di gioco dinamiche rendono queste slot particolarmente coinvolgenti.
Accanto alle slot, non mancano i giochi da tavolo classici come roulette, blackjack e baccarat. Spesso sono disponibili in diverse varianti, pensate per soddisfare sia i giocatori più esperti sia coloro che preferiscono regole semplici e immediate. Questa varietà contribuisce a creare un’esperienza di gioco personalizzabile.
Un’altra sezione molto apprezzata è quella dei casinò live. Grazie allo streaming in tempo reale, i giocatori possono interagire con croupier professionisti e vivere un’esperienza simile a quella di un casinò fisico, senza rinunciare alla comodità del gioco online.
I metodi di pagamento rappresentano un ulteriore fattore di scelta. I casinò non AAMS più moderni offrono diverse opzioni, come carte di credito, portafogli elettronici e talvolta soluzioni alternative. Questa flessibilità consente agli utenti di scegliere il metodo più adatto alle proprie esigenze, garantendo depositi e prelievi rapidi.
Nonostante la possibilità di iniziare con un deposito ridotto, è fondamentale mantenere un approccio responsabile al gioco. Stabilire un budget, rispettare i propri limiti e giocare solo con somme che ci si può permettere di perdere sono regole essenziali per evitare comportamenti rischiosi.
Molti casinò affidabili mettono a disposizione strumenti per il gioco responsabile, come limiti di deposito, periodi di pausa e opzioni di autoesclusione. Questi strumenti aiutano i giocatori a mantenere il controllo e a vivere il gioco come una forma di intrattenimento, non come una fonte di stress.
In conclusione, i casinò non AAMS con deposito minimo di 10 euro rappresentano una soluzione interessante per chi cerca flessibilità, varietà e un ingresso graduale nel mondo del gioco online. Grazie a un equilibrio tra sicurezza, offerta di giochi e gestione consapevole del budget, queste piattaforme continuano a guadagnare popolarità tra utenti di ogni livello di esperienza.
I’m Jane Austen, a skilled content writer with the ability to simplify any complex topic. I focus on delivering valuable tips and strategies throughout my articles.
What references were used to make this post?