Introduction
Object detection is a crucial task in computer vision, with applications ranging from surveillance and autonomous vehicles to medical imaging. YOLO (You Only Look Once) is a famous family of real-time object detection algorithms, and YOLOv8 represents the latest iteration, offering improved performance and versatility.
Fine-tuning YOLOv8 allows you to tailor the model to your specific dataset, enhancing its ability to recognize objects accurately.
In this guide, we will walk you through the process of Use Fine Tune YOLOv8 for optimal results.
Understanding YOLOv8
Before diving into fine-tuning, it’s essential to have a basic understanding of YOLOv8. YOLOv8, developed by Alexey Bochkovskiy, is an evolution of the YOLO architecture. It stands out for its speed and accuracy, making it suitable for real-time applications.
YOLOv8 uses a single neural network to predict bounding boxes and class probabilities directly from full images, making it a one-stage object detection model.
Prerequisites
Before you start fine-tuning YOLOv8, ensure you have the following prerequisites:
- YOLOv8 Source Code: Clone the YOLOv8 repository from the official GitHub page (https://github.com/AlexeyAB/darknet) to access the source code.
- Training Data: Prepare a well-annotated dataset with images and corresponding bounding box annotations for the objects of interest.
- Configuration Files: YOLOv8 relies on configuration files (.yaml) to specify model settings. Make sure you have the default configuration file and a modified version tailored to your dataset.
- Pre-trained Weights: Download the pre-trained YOLOv8 weights from the official repository to initialize your model.
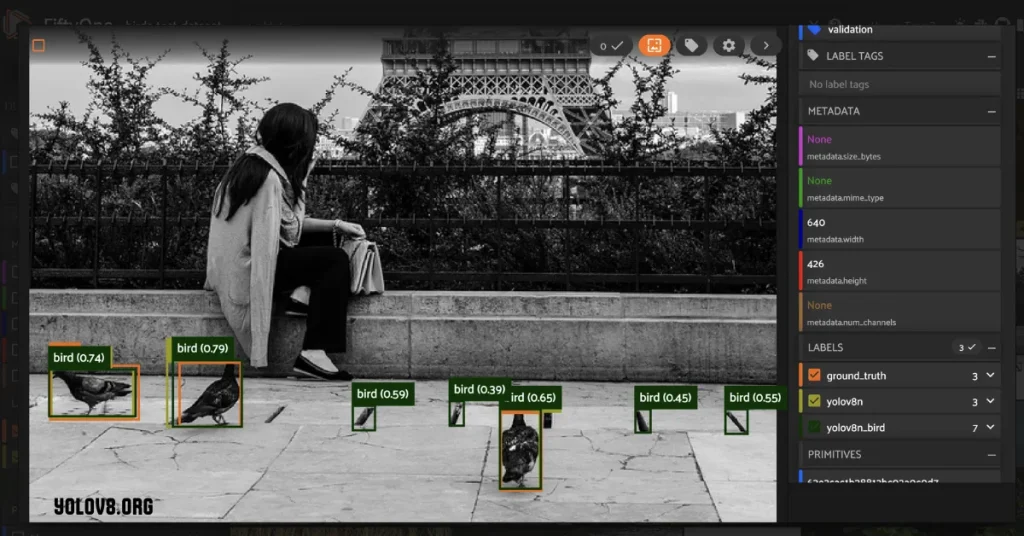
What is Fine Tune YOLOv8?
Fine-tuning YOLOv8 refers to the process of adjusting and optimizing the pre-trained YOLOv8 (You Only Look Once version 8) model for a specific task or dataset. YOLOv8 is a popular object detection algorithm that can efficiently and accurately detect and classify objects in images and videos.
Fine-tuning allows users to adapt the model to their particular needs, improving its performance on a specific domain or dataset.
The fine-tuning process typically involves taking a pre-trained YOLOv8 model, which has been trained on a large and diverse dataset, and fine-tuning it on a smaller, domain-specific dataset.
This is especially useful when the target objects or scenarios differ significantly from those in the original training data. Fine-tuning helps the model learn the specific characteristics and features relevant to the new dataset, enhancing its ability to detect and classify objects accurately.
To fine-tune YOLOv8, users usually need a labeled dataset specific to their application, containing images annotated with bounding boxes around the objects of interest.
The fine-tuning process involves adjusting the model’s weights based on the new dataset while retaining the knowledge gained during the initial pre-training on a more extensive dataset. This transfer of knowledge helps the model generalize well to the new domain.
Fine-tuning YOLOv8 requires expertise in computer vision, deep learning frameworks, and the YOLO algorithm itself. Users typically leverage tools, such as the YOLOv8 codebase and associated libraries, to facilitate the fine-tuning process.
By fine-tuning YOLOv8, practitioners can tailor the model to their specific needs, achieving better performance and accuracy in object detection tasks within their targeted domain.
Fine-Tuning Steps: How to Use?
Now, let’s walk through the steps of fine-tuning YOLOv8 use:
1: Dataset Preparation
Organize your dataset into training and validation sets. Ensure that each image is labelled with bounding box annotations, and the classes match those defined in your configuration file.
2: Configuration Adjustment
Modify the YOLOv8 configuration file to suit your dataset. Update parameters such as the number of classes, anchor boxes, and paths to your training and validation datasets.
3: Pre-trained Weights
Initialize your YOLOv8 model with pre-trained weights. This step leverages the knowledge gained from a large dataset and accelerates the convergence of your model on a specific task.
4: Training
Initiate the training process using the following command:
- bash
- python train.py –img-size 640 –batch-size 16 –epochs 100 –data your_custom_data. yaml. –cfg your_custom_config. yaml –weights yolov8.weights –name custom_model
Adjust parameters such as img-size, batch-size, and epochs based on your hardware capabilities and dataset size.
5: Evaluation
After training, assess your model’s performance on the validation set using the following command:
- bash
- python test.py –weights runs/train/custom_model/weights/best.pt –data your_custom_data.yaml. yaml –img-size 640
Evaluate metrics such as mAP (mean Average Precision) to gauge the model’s accuracy.
6: Fine-Tuning Iterations
Fine-tuning is an iterative process. Analyse the results, tweak your configuration, and continue training until your model achieves satisfactory performance.
7: Inference
Once satisfied with the model, use it for inference on new data:
- bash
- python detect.py –weights runs/train/custom_model/weights/best.pt –img-size 640 –source your_test_images/
Tips for Effective Fine-Tuning
- Data Augmentation: Augment your training data with transformations like rotation, flipping, and scaling to improve model generalization.
- Learning Rate Scheduling: Experiment with learning rate schedules to fine-tune the model more effectively.
- Hyperparameter Tuning: Adjust hyperparameters, such as the batch size and number of epochs, to find the optimal configuration for your dataset.
- Transfer Learning: If your dataset is small, Training YOLOv8 on a custom dataset, consider leveraging transfer learning by fine-tuning on a larger, related dataset before fine-tuning on your specific task.
- Model Interpretation: Use visualization tools to interpret the model’s predictions and refine the training process.
By following these steps and tips, you can fine-tune YOLOv8 for your specific object detection task, enhancing its accuracy and reliability on your custom dataset. Keep in mind that fine-tuning requires a balance between underfitting and overfitting, so regularly monitor your model’s performance and adjust accordingly. Happy fine-tuning!
FAQS (Frequently Asked Questions)
Q#1: What is fine-tuning YOLOv8 and why should I do it?
Fine-tuning YOLOv8 involves taking a pre-trained object detection model and further training it on your specific dataset. This allows the model to adapt to the unique objects and patterns in your data, potentially leading to improved accuracy and performance on your specific task.
Q#2: What do I need before I start fine-tuning?
- A dataset of images containing the objects you want your model to detect. This dataset should be annotated with bounding boxes around the objects.
- A pre-trained YOLOv8 model, such as YOLOv8n, YOLOv8s, or YOLOv8m.
- Hardware with sufficient GPU memory to handle the training process.
Q#3: How do I prepare my dataset for fine-tuning?
Your dataset needs to be in a format that YOLOv8 can understand. This typically involves creating text files with information about each image, including its filename, size, and the bounding boxes of the objects it contains. Several tools can help with this process, such as VGG Image Annotator (VIA) or LabelImg.
Q#4: What are the critical steps involved in fine-tuning?
- Prepare your data: Ensure your dataset is formatted correctly and split into training, validation, and (optionally) test sets.
- Choose a pre-trained model: Select a YOLOv8 model with a balance of accuracy and speed suitable for your hardware and application.
- Configure training: Adjust hyperparameters like learning rate, batch size, and number of epochs based on your dataset and hardware.
- Fine-tune the model: Train the pre-trained model on your dataset using the chosen configuration.
- Evaluate performance: Assess the model’s accuracy on the validation or test set to measure its effectiveness.
Q#5: What are some common challenges in fine-tuning YOLOv8?
- Data quality: Insufficient or poorly annotated data can lead to suboptimal performance.
- Hyperparameter tuning: Finding the right balance of hyperparameters requires experimentation and expertise.
- Hardware limitations: Training large models on limited GPU memory can be slow and resource-intensive.
Q#6: Are there any resources available to help me get started?
Yes, there are several resources available online to assist you with fine-tuning YOLOv8:
- Ultralytics YOLOv8 documentation: https://docs.ultralytics.com/
- Fine-tuning YOLOv8 with Custom Dataset tutorial: https://medium.com/@yongsun.yoon/fine-tuning-yolov8-using-custom-dataset-generated-by-open-world-object-detector-5724e267645d
- Fine-tuning YOLOv8 for Image Segmentation with Comet: https://www.comet.com/site/blog/fine-tuning-yolov8-for-image-segmentation-with-comet/
- YOLOv8 GitHub repository: https://github.com/ultralytics/ultralytics
Remember, fine-tuning YOLOv8 can be a complex process, and achieving optimal results requires careful consideration of your dataset, hardware, and chosen configuration. Don’t hesitate to consult the resources above and experiment to find the approach that works best for your specific needs.
Recent Posts
- YOLOv8 Aimbot: Challenges and Opportunities
- YOLOv8 Train Custom Dataset: Train Your Own Object Detection Model
- YOLOv8 GPU: Unlocking Power with GPUs
- YOLOv8 Dataset Format: Mastering YOLOv8 Dataset Preparation
- YOLOv8 PyTorch Version: Speed and Accuracy in Your PyTorch Projects
I’m Jane Austen, a skilled content writer with the ability to simplify any complex topic. I focus on delivering valuable tips and strategies throughout my articles.